Deux mémoires
Un processus qui s'arrête n'efface pas ce qu'il a terminé. Il efface seulement ce qu'il n'a pas encore écrit ailleurs.
Le DAG ordonne l'exécution. Mais deux choses peuvent rompre cet ordre, et ce sont les deux questions que l'épisode précédent a laissées ouvertes. La première : une règle qui échoue pour une raison transitoire (un timeout LLM, un outil qui ne répond plus) et qu'il serait absurde d'abandonner à la première tentative. La seconde : un processus qui s'arrête (un pod qui redémarre, une instance qui sature), emportant avec lui tout ce qui vivait en mémoire.
Ces deux cas ne se ressemblent pas. L'un est local, circonscrit à une règle. L'autre est global, il touche tout ce qui tourne. Et pourtant, la résilience face à l'un comme à l'autre repose sur le même principe : déposer l'état là où le processus ne peut pas l'emporter en mourant. La mémoire, ici, n'est pas une optimisation, c'est une condition de correction.
Trois niveaux de défaillance
Commençons par le cas local : une règle qui échoue. Les raisons sont nombreuses, et la plupart sont transitoires. Un timeout LLM. Un outil qui ne répond plus. Un quota momentanément dépassé. La même règle, relancée trente secondes plus tard, réussirait. L'abandonner à la première tentative serait un gaspillage.
L'architecture de résilience se déploie en trois niveaux, du plus immédiat au plus définitif.
Le premier niveau est en mémoire. PassExecutionOrchestrator tente une à deux fois de relancer la règle défaillante, sans délai significatif, sans état persisté. C'est la réponse aux erreurs les plus transitoires, la majorité des cas. Si la règle réussit à la deuxième tentative, le reste du graphe n'en a jamais su.
Si ces retries immédiats échouent, le second niveau entre en jeu. Le statut de la règle est persisté dans Redis Sentinel : failed_attempt_1, failed_attempt_2, jusqu'au maximum configuré. EvaluationModule publie alors un message de retry sur un exchange RabbitMQ dédié, avec un TTL croissant : trente secondes pour la première tentative différée, deux minutes pour la deuxième, dix minutes pour la troisième. C'est le pattern classique de delay queue RabbitMQ : un exchange mort-lettre qui requeue le message après expiration du TTL. ReEvaluateUseCase reçoit ce message et reprend l'exécution depuis l'état persisté. Les règles déjà réussies ne sont pas relancées, seule la règle défaillante est rejouée dans son contexte de dépendances.
Le troisième niveau est l'arrêt. Après N tentatives (trois par défaut, configurable par règle), la règle est marquée permanently_failed. C'est à ce stade seulement que le DAG en tire les conséquences : les règles qui dépendaient de la règle définitivement échouée sont ignorées, les passes concernées publient un résultat partiel. Les branches indépendantes du graphe, elles, n'en sont jamais informées. Elles continuent.

Retour de R&D : une delay queue en RabbitMQ n'est pas une primitive native, c'est un pattern construit à partir de deux mécanismes. Une queue sans consommateur reçoit les messages avec un TTL configuré à la publication. À l'expiration du TTL, RabbitMQ considère le message comme dead-lettered et le route vers un exchange mort-lettre (Dead Letter Exchange, DLX), qui le redirige vers la queue cible. Le résultat : un message publié dans la delay queue apparaît sur la queue de travail après exactement TTL millisecondes, sans qu'aucun scheduler externe n'ait été nécessaire. C'est un mécanisme natif, simple, qui ne demande qu'une configuration d'exchange.
La granularité du retry à la règle n'est pas un détail. Elle est rendue possible par le DAG au niveau des règles : puisque le système sait exactement quelles règles ont réussi et lesquelles ont échoué, il peut reprendre avec précision. Retenter une passe entière pour une règle défaillante gaspillerait ce que le graphe sait déjà.
Le message qui attend
Passons au cas global : un processus qui s'arrête en pleine exécution. Cette fois, ce n'est pas une règle qui défaille, c'est l'ensemble du travail qui vient de disparaître. La première mémoire qui nous aide n'appartient pas à ce micro-service. Elle appartient à RabbitMQ.
Quand EvaluationController reçoit un message evaluation.execute, il ne l'acquitte pas immédiatement. Il attend d'abord d'avoir récupéré la configuration via NATS, d'avoir initialisé le job, d'avoir émis evaluation.started. Ce n'est qu'à ce moment que l'ACK est envoyé, comme confirmation que le travail a effectivement commencé.
La conséquence est précise : tant que l'ACK n'est pas envoyé, RabbitMQ conserve le message. Si le pod s'arrête avant d'avoir pu ACKer, le message est relivré. L'évaluation recommence depuis le début, comme si rien ne s'était passé.
Or si le crash survient après l'ACK, pendant l'exécution des règles, RabbitMQ ne sait plus rien. Le message est acquitté, considéré comme traité. La relivraison automatique ne se déclenche pas. C'est là qu'intervient la seconde mémoire.
L'état dans Redis
La seconde mémoire est Redis Sentinel, déjà dans l'infrastructure, déjà utilisé pour le cache du VectorStore. Chaque règle complétée avec succès y écrit immédiatement son résultat. Chaque règle en cours de retry y écrit son statut. La structure est simple :
attempt:{attemptId}:rule:{ruleId}:result → RuleResult JSON (règle terminée)
attempt:{attemptId}:rule:{ruleId}:status → failed_attempt_N (règle en retry)
Un TTL de sept jours garantit que ces clés s'effacent automatiquement, sans intervention, sans nettoyage manuel.
La granularité est au niveau de la règle, pas de la passe. Ce n'est pas une coïncidence : le DAG fonctionne à la granularité des règles, le mécanisme de retry fonctionne à la granularité des règles. La recovery applique la même cohérence. Si neuf règles sur dix ont terminé avant le crash, une seule doit être rejouée. Redis le sait, et ReEvaluateUseCase ne demande pas plus que ce que Redis peut dire.
Pourquoi Redis plutôt qu'un système de fichiers ? La question mérite d'être posée directement. Un fichier JSON par règle aurait fonctionné : c'est lisible, c'est simple, ça ne nécessite pas de réseau. Or cela aurait introduit une dépendance d'infrastructure supplémentaire : des volumes persistants montés sur chaque pod, dimensionnés, sauvegardés, réconciliés quand un pod reprend le travail d'un autre. Redis Sentinel, lui, est déjà là. Il est accessible depuis n'importe quelle instance, sans montage de volume. Ses écritures sont atomiques, donc pas de risque d'état partiel en cas d'interruption au milieu d'une écriture. Et la dépendance existe déjà : si Redis est indisponible, le VectorStore cache ne fonctionne plus, et les agents ne peuvent plus lire le code du candidat. La recovery via Redis n'ajoute pas un nouveau point de défaillance, elle s'inscrit dans une dépendance déjà contractée.
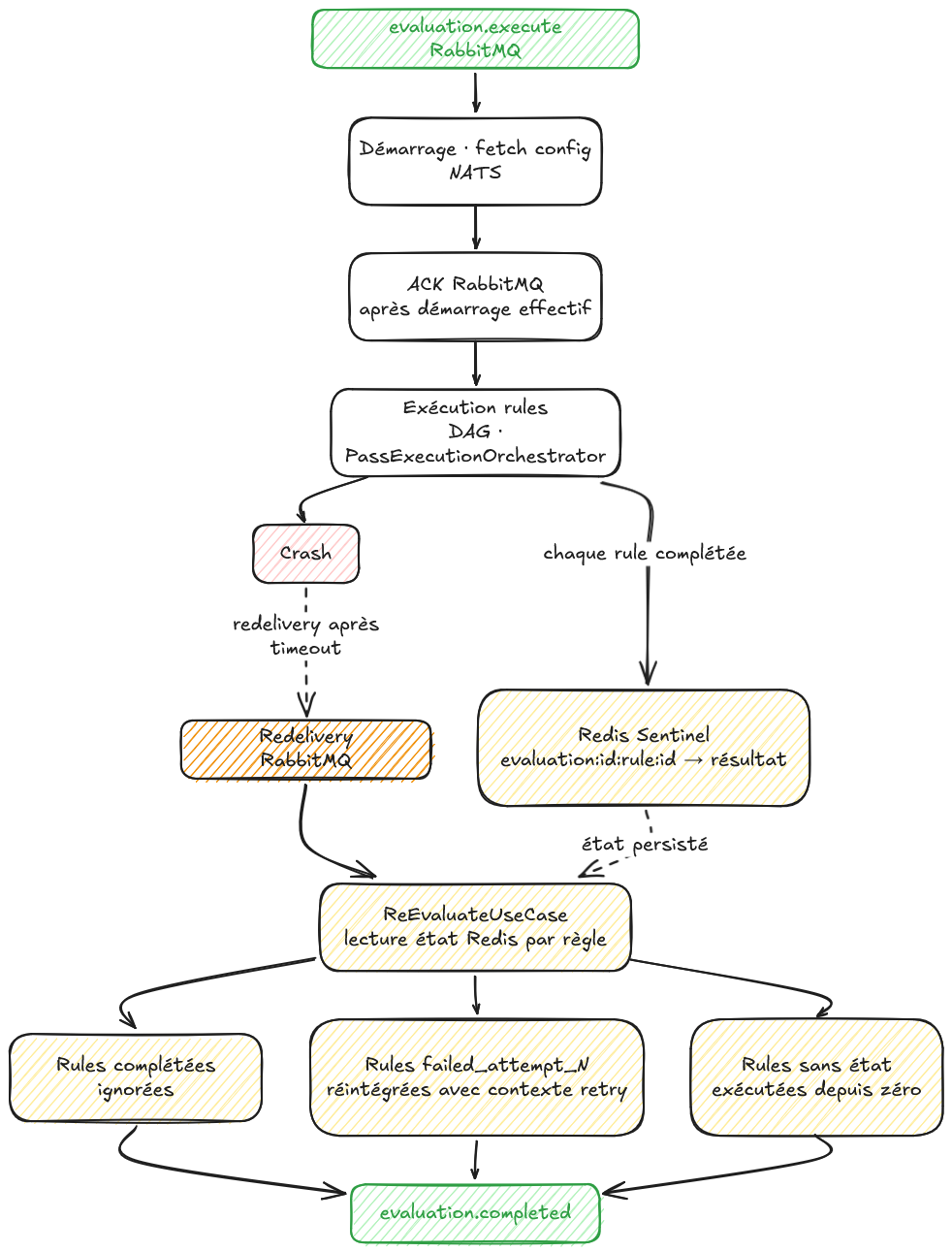
Quand le message est relivré (quel que soit le trigger, crash ou retry avec délai), ReEvaluateUseCase commence par une lecture Redis. Il récupère tous les états connus pour cet evaluationId. Trois catégories émergent.
Les règles dont le résultat est présent dans Redis sont terminées. ReEvaluateUseCase les charge directement, leurs RuleResult sont intégrés dans le plan sans relancer AgentService. Les passes dont toutes les règles sont terminées de cette façon sont complètes, sans qu'une seule règle soit réexécutée.
Les règles dont le statut est failed_attempt_N sont en cours de retry. Elles sont réintégrées dans le plan d'exécution avec leur compte de tentatives. Le backoff exponentiel reprend là où il s'était arrêté.
Les règles sans aucune entrée Redis n'ont jamais été exécutées, ou leur résultat n'a pas eu le temps d'être écrit avant le crash. Elles démarrent depuis zéro.
Ce que ReEvaluateUseCase reconstruit, c'est le DAG dans son état au moment du crash, non pas depuis la mémoire du processus mort, mais depuis la projection fidèle qu'en a conservé Redis.
RabbitMQ garantit que le message arrive. Il ne garantit pas que le travail soit fait.
Redis garantit que ce qui a été fait n'est pas refait. Il ne garantit pas que le message revient.
Aucune des deux mémoires ne suffit seule. J'ai mis un moment à comprendre que ces deux mémoires ne se redondent pas, elles se complètent. Supprimer l'une des deux ne renforce pas l'autre, ça crée un angle mort. RabbitMQ sans Redis : la relivraison déclenche une exécution depuis zéro, toutes les règles déjà terminées sont rejouées, leur coût LLM est dupliqué. Redis sans RabbitMQ : l'état est conservé, mais personne ne sait qu'il faut reprendre l'exécution.
Il reste une limite à nommer. Si le crash survient dans la fenêtre entre la complétion d'une règle et son écriture dans Redis (quelques millisecondes), cette règle sera rejouée. C'est la sémantique d'at-least-once : préférable à l'absence de résultat, mais qui implique que les règles doivent être idempotentes. Une règle exécutée deux fois sur le même code doit produire le même verdict. C'est une contrainte de conception sur AgentService, non sur l'infrastructure. Ce qui est, dans un sens, rassurant : cela signifie qu'un agent qui évalue correctement le même code deux fois de suite est simplement un agent fiable.
La prochaine fois : EvaluationModule est refermé. Son cycle de vie, son DAG, sa résilience. Six épisodes pour poser le cœur d'AgenticLayer, ses modules, ses garanties. Avant de poursuivre avec ce qui l'entoure (VectorStoreModule, l'indexation, le reste du système), un regard en arrière s'impose.