Ce que les noms décident
L'évaluation technique est l'un des rares domaines où tout le monde s'accorde sur l'objectif: mesurer les compétences et où presque personne ne s'accorde sur ce qu'on mesure. Cette contradiction n'est pas un défaut de méthode. Elle est constitutive du langage naturel, qui tolère l'ambiguïté et s'en nourrit. "Il est bon." "Il a le niveau." "Il manque de maturité." Ces formulations circulent dans les debriefs avec une apparence d'évidence et elles recouvrent des réalités fondamentalement différentes selon celui qui les prononce.
Ce projet est une tentative de construire cette rigueur sans pour autant trancher à la place de ceux qui utilisent le système. L'objectif n'est pas d'imposer une définition de la compétence mais d'en fournir l'infrastructure pour que chacun puisse exprimer la sienne avec précision, de façon traçable, défendable, et révisable. AgenticLayer, le microservice que ce journal documente, est la pièce qui exécute cette promesse : il évalue du code source à partir de critères définis par d'autres, avec la rigueur que cette définition exige.
Mais avant d'entrer dans l'architecture, il faut poser les mots. Ce que chacun signifie dans ce système, avec précision.
Ce qu'une compétence n'est pas
La première tentation est de réduire une compétence à une technologie : "maîtrise React", "connaît Docker". Ce n'est pas une compétence mais une déclaration. Elle ne dit rien sur ce qu'un candidat est capable de faire avec React, dans quel contexte, sous quelle contrainte, à quel niveau de profondeur.
Dans ce système, une compétence est une capacité comportementale observable : quelque chose qu'un individu démontre à travers ce qu'il produit, dans un contexte délimité, à un niveau mesurable. Elle est gradable, décrits en termes de ce qu'on voit faire, pas de ce qu'on sait réciter. Elle est contextuelle, la même compétence ne se manifeste pas de la même façon dans un algorithme de scheduling et dans un design d'API. Et elle est construite dans le temps: plusieurs évaluations, plusieurs contextes, un signal qui s'affine.
Ce que le système ne décide pas, c'est quelles compétences existent, ni combien, ni ce qu'elles signifient. C'est entièrement configurable. Ce qu'on y met, c'est la vision de celui qui configure.
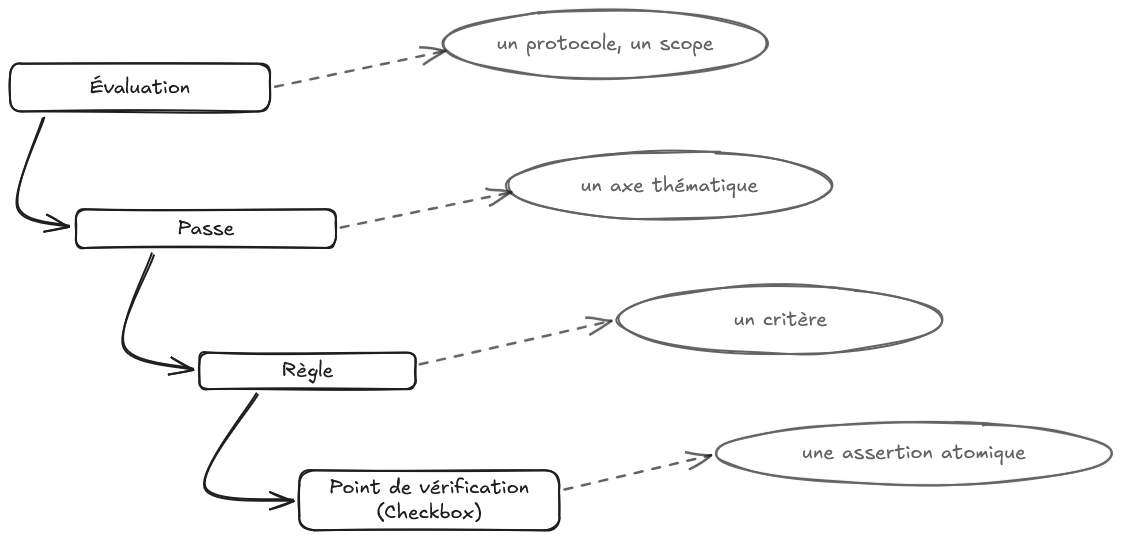
Évaluation, passe, règle, point de vérification
Ces quatre termes décrivent les niveaux de granularité d'une observation. La distinction entre chaque niveau reflète une réalité du domaine.
Une évaluation est un protocole d'observation délimité : un contexte, un scope, un ensemble de questions auxquelles on cherche à répondre. Elle peut s'étaler sur une journée de travail, parfois trois ou quatre,un projet à livrer dans un contexte réel, une architecture à concevoir sous contrainte, un refactoring à mener sans filet. Ce n'est pas un exercice synthétique. C'est une fenêtre ouverte sur la façon dont quelqu'un travaille, pense, structure, et tient la durée. C'est précisément ce temps long qui permet d'observer des compétences croisées. Celles qui n'apparaissent que quand plusieurs dimensions du travail sont sollicitées simultanément.
Une passe est un axe thématique à l'intérieur d'une évaluation. Elle regroupe ce qui relève du même angle d'observation: la conformité de l'implémentation, la qualité du code, la couverture des cas limites. Les passes d'une évaluation peuvent dépendre les unes des autres ; certaines s'exécutent en parallèle, d'autres attendent qu'une précédente soit terminée.
Une règle est un critère à l'intérieur d'une passe. Elle pose une question : "la gestion des erreurs est-elle intentionnelle ?" Elle peut être complexe, comporter plusieurs sous-questions. Elle produit un verdict.
Un point de vérification ou checkbox est l'unité atomique. C'est une assertion binaire, non ambiguë, vérifiable sans interprétation : soit elle est vraie, soit elle est fausse. Pas "le code est lisible". Plutôt : "les noms de variables décrivent leur intention sans abréviation". L'ambiguïté est résolue au moment de la définition, c'est là que le travail intellectuel se fait, pas au moment de l'évaluation.
Ces quatre entités vivent dans la base de données graphe: ArangoDB. C'est dans le graphe qu'AgenticLayer ira chercher sa configuration au moment de l'exécution, par une requête sur le domaine, pas dans un fichier statique.
Ce qui relie les deux : le skillGrid
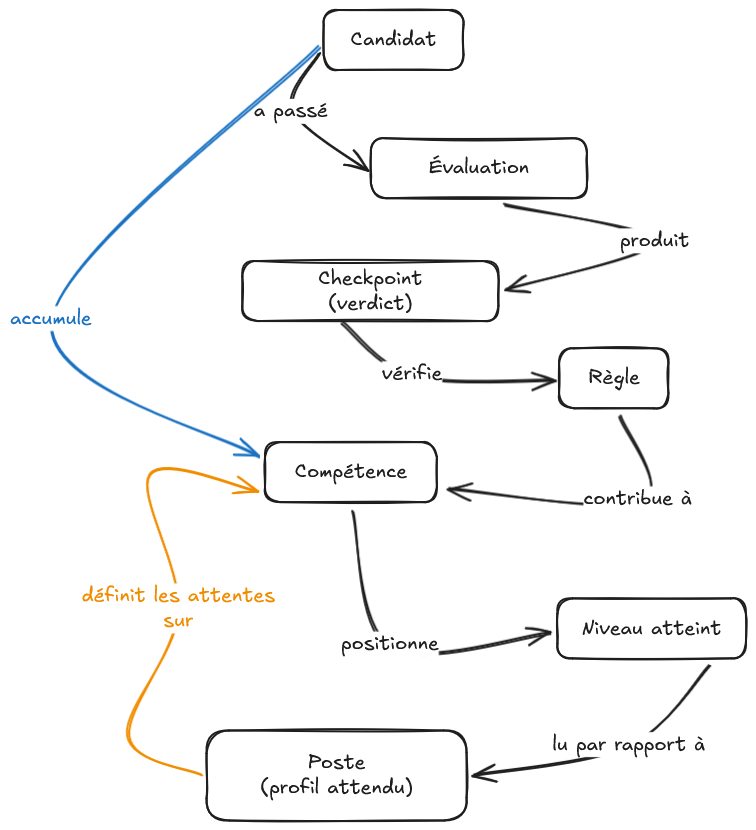
Le modèle de compétences et la structure d'évaluation sont deux graphes distincts. Ce qui les connecte, c'est le skillGrid : la déclaration explicite de comment les résultats d'une évaluation alimentent les compétences, avec quels poids.
Le skillGrid déclare, pour chaque compétence : quelles règles de quelles évaluations y contribuent, et dans quelle mesure. Une même règle peut contribuer à plusieurs compétences. Une même compétence peut être alimentée par plusieurs évaluations avec des poids différents selon la pertinence du scénario.
Ces poids ne sont pas calculés par le système mais sont déclarés par celui qui configure. C'est ici que réside l'intelligence de la grille : non pas dans un algorithme qui déciderait de l'importance relative des signaux, mais dans une décision explicite, argumentable, révisable. Si une pondération change, on sait pourquoi, par qui, à quelle version.
Mais il y a quelque chose de plus profond ici que de la personnalisation. L'introduction l'a posé : tout le monde croit savoir ce que signifie une compétence, et presque personne ne la définit de la même façon. Un recruteur voit la rigueur formelle. Un tech lead voit le raisonnement sous contrainte. Un manager voit l'autonomie décisionnelle. Ces visions ne sont pas fausses mais... situées, et le plus souvent implicites. Le skillGrid les force à devenir explicites.
C'est ce que j'entends par "laisser la main sans parti pris". Le système ne tranche pas entre ces visions. Il fournit la structure pour que chacune puisse s'exprimer avec la même rigueur. Deux organisations qui configurent leur skillGrid différemment ne font pas la même chose. Elles mesurent chacune ce qui compte pour elles. Mais elles le mesurent honnêtement : de façon traçable, défendable, révisable quand leur vision évolue. C'est l'application technique du principe de l'introduction : l'abstraction technique ne doit pas choisir entre les visions mais les rendre toutes rigoureuses.
Le poste : une grille de lecture
La grille de compétences dit ce qu'un candidat sait faire et à quel niveau. Elle ne dit pas si ce candidat convient pour un rôle particulier. Pour répondre à cette question, il faut un deuxième niveau de matrice: le poste.
Un poste est une déclaration de ce qui est attendu et non une liste de mots-clés. C'est une composition pondérée de compétences à des niveaux cibles. "Pour ce rôle, je cherche un niveau Intermediate en conception système, Junior+ en implémentation de règles métier, et Beginner au minimum en tests automatisés." Cette déclaration est entièrement la responsabilité du recruteur qui définit le besoin.
Ce qui rend ce niveau structurant, c'est qu'il révèle les mêmes variations de vision que la couche de skillGrid. Deux entreprises qui recrutent un "développeur backend senior" n'ont pas nécessairement la même définition du mot "senior". L'une met l'accent sur la profondeur algorithmique. L'autre sur la capacité à livrer sous contrainte. Une troisième sur la lecture d'un système existant et la capacité à l'étendre sans le casser. La même compétence, au même niveau, dit quelque chose de différent selon le prisme du poste qui la lit.
C'est à ce niveau que les deux matrices se rejoignent. La première dit comment le signal brut d'une évaluation devient un score de compétence et c'est la responsabilité des skillGrid. La seconde dit comment un ensemble de scores de compétences se compare aux attentes d'un rôle (c'est la responsabilité du poste). Entre les deux, le profil d'un candidat n'est jamais un absolu. Il est toujours lu par rapport à une définition, et cette définition appartient à celui qui recrute.
Le graphe comme modèle
Tous ces termes: compétences, évaluations, passes, règles, checkpoints, skillGrid, candidats, résultats, sont des entités en relation. Ce ne sont pas des lignes dans des tables séparées. Ce sont des nœuds dans un graphe, reliés par des arêtes qui portent elles-mêmes de la sémantique : "cette règle appartient à cette passe", "ce checkpoint a été vérifié avec cette conclusion", "ce résultat contribue à cette compétence avec ce poids", "ce candidat a atteint ce niveau sur cette compétence à cette date".
C'est ArangoDB qui porte ce graphe. Non pas par goût de la nouveauté, mais parce que ce que le système cherche à modéliser est un graphe. Les requêtes qui importent: "quel est l'état actuel des compétences de ce candidat, en agrégeant toutes ses évaluations passées ?", sont des traversées de graphe. Les modéliser dans un schéma relationnel reviendrait à aplatir ce qui est fondamentalement réticulaire.
Ce graphe s'enrichit à chaque évaluation. Il ne remplace pas les résultats précédents, il les accumule. C'est dans cet enrichissement progressif que réside la valeur du système : une compétence ne se lit pas dans une évaluation, elle se lit dans leur accumulation.
AgenticLayer dans ce système
Le vocabulaire est posé. Il reste à nommer la pièce que ce journal va suivre et à dire précisément ce qu'elle fait dans ce domaine.
AgenticLayer est le microservice qui exécute les évaluations. Quand une demande arrive (un candidat à évaluer sur une évaluation), une configuration de passes et de règles à appliquer, un dépôt de code à analyser, c'est lui qui prend en charge l'exécution. Il interroge ArangoDB pour récupérer la structure de l'évaluation, il déploie des agents LLM qui explorent le code source comme un enquêteur explore une scène, et il produit un verdict structuré sur chaque point de vérification. Ces verdicts sont ensuite transmis au microservice ArangoDB, qui les intègre dans le graphe.
Son rôle est délibérément étroit. Il n'authentifie pas les requêtes. Il ne calcule pas les scores de compétences. ça, c'est une traversée de graphe que l'autre service effectue une fois les verdicts persistés. Il ne gère pas le cycle de vie d'un candidat. Ce qu'il fait, et seulement lui, c'est transformer une configuration d'évaluation en preuves observées sur un dépôt de code.
Or ce que le mot "agentique" recouvre, pourquoi des agents LLM plutôt qu'un correcteur déterministe, comment la boucle est structurée, où vivent les responsabilités à l'intérieur du microservice: c'est ce que les épisodes qui suivent documentent. Ce premier épisode avait un seul objectif : que les mots soient en place avant que l'architecture commence.
La prochaine fois : AgenticLayer s'inscrit dans un écosystème distribué qu'il n'a pas conçu. Un gateway, un microservice de persistance graphique, des transports, des bases de données partagées. Comment ces pièces se parlent-elles, et pourquoi ces choix-là plutôt que d'autres ?