Le temps d'une évaluation
Ce qui orchestre ne fait pas. C'est précisément pour cela qu'il peut coordonner.
L'épisode précédent a posé la vie intérieure d'AgentModule : quatre sous-modules, des scopes choisis pour que quarante boucles puissent tourner sans se contaminer. J'ai décrit cette mécanique comme si elle se suffisait à elle-même. Elle ne se suffit pas.
AgentService évalue une règle. Une règle seule. Il ne sait pas qu'il existe d'autres règles. Il ne sait pas qu'elles sont organisées en passes. Il ne sait pas qu'un verdict global doit en émerger. Il ne sait même pas ce que "évaluer" veut dire pour le métier : il applique une boucle agentique à ce qu'on lui donne et rend ce qu'il a trouvé.
Aujourd'hui, ce qu'on lui donne, c'est une règle d'évaluation. Demain, ce pourrait être tout autre chose : un tour d'agent conversationnel qui aide un candidat bloqué sur un exercice, une exploration automatique de code pour en extraire une cartographie, une analyse de progression de compétences sur la durée. À chaque fois, le même moteur : recevoir un contexte, compiler un prompt, appeler un LLM, exécuter des tools, surveiller les dérives, rendre un résultat structuré. Ce qui change, c'est ce qu'on lui demande, et ce qui attend son résultat. L'ingénierie reste la même. Le workflow, lui, est propre à chaque usage.
Cette ignorance est ce qui lui donne sa valeur. C'est aussi ce qui rend nécessaire tout ce qui l'entoure. Un moteur générique ne devient utile qu'à condition qu'on l'installe dans un workflow spécifique, un workflow qui, lui, connaît le domaine. Ce workflow, aujourd'hui, c'est EvaluationModule. Cet épisode raconte comment un moteur générique devient le cœur d'une évaluation complète sans jamais le savoir.
L'entrée en scène
Tout commence par un message. Sur la queue RabbitMQ evaluation.execute, un événement arrive, portant un identifiant d'évaluation, une référence au candidat, une référence à la configuration. Rien de plus. Le message est un pointeur, pas un payload.
Ce choix n'est pas une économie. C'est une séparation. La configuration complète (les passes, les règles, les points de vérification atomiques) vit dans le micro-service graph (arangoDB), qui possède les données métier. Elle y a été construite, validée, versionnée. La transporter dans le message serait la dupliquer sans raison, et créer un couplage entre le service qui déclenche l'évaluation et le contenu métier qui évolue indépendamment.
La première chose que fait EvaluationModule, c'est donc de demander. Via NATS, il interroge le micro-service graph (arangoDB) et récupère la structure complète de l'évaluation. Ce n'est qu'une fois cette configuration en main qu'il acquitte le message RabbitMQ. Pas à la réception : après le démarrage effectif du job.
Cette orchestration est portée par un use case. Pas par un contrôleur, pas par un service générique : un use case, au sens précis que ce terme a dans l'architecture hexagonale.
Retour de R&D : dans l'architecture hexagonale (aussi appelée ports & adapters), un use case est une classe qui porte un scénario métier complet, indépendamment de la façon dont il est déclenché. Un même use case peut être appelé depuis un contrôleur HTTP, depuis un consommateur de message RabbitMQ, ou depuis une commande CLI : la logique métier reste la même. Cette indépendance vis-à-vis du mécanisme d'entrée est l'idée centrale du pattern. Ce qui déclenche l'évaluation n'a pas à savoir comment elle fonctionne ; la logique d'évaluation n'a pas à savoir qui la déclenche.
Un use case se distingue d'un service classique sur deux points. D'abord, il représente un scénario, pas un ensemble de méthodes liées :
ExecuteEvaluationUseCaseexpose une seule méthode publique,execute. Ensuite, il compose d'autres éléments (orchestrateurs, services de domaine, ports externes) sans porter lui-même de logique métier complexe. Il est le chef d'orchestre d'un scénario spécifique.
Trois use cases existent dans EvaluationModule, chacun portant un scénario distinct. ExecuteEvaluationUseCase est le flux principal : une évaluation complète depuis la réception du message jusqu'à la publication du verdict. ExecuteSelectiveEvaluationUseCase couvre le cas où seul un sous-ensemble de règles doit être réévalué, sans reprendre l'intégralité des passes. ReEvaluateUseCase gère la reprise après interruption, en lisant l'état persisté règle par règle dans Redis pour ne relancer que ce qui n'est pas encore terminé. Trois scénarios, trois use cases, plutôt qu'un seul use case à drapeaux qui porterait les trois à la fois et dont les tests auraient l'air amusants à écrire.
Descendre jusqu'à la boucle
Un use case ne fait pas tout lui-même. Il délègue. Et ce qu'il délègue se lit comme une descente.
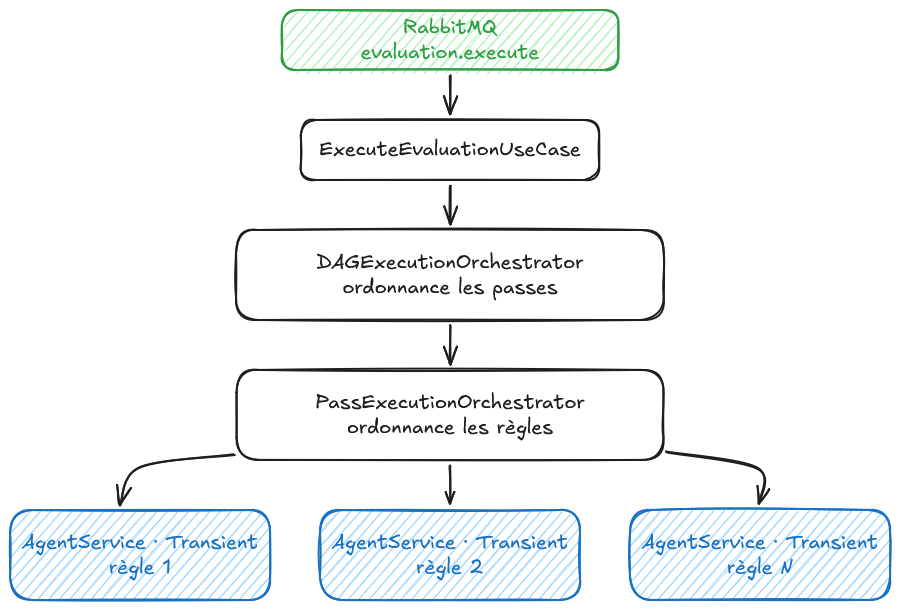
Le schéma se parcourt du haut vers le bas, et chaque niveau est plus étroit que le précédent. En haut, une évaluation complète. En bas, une règle seule portée par une instance d'AgentService. Entre les deux, deux orchestrateurs qui réduisent progressivement la portée du raisonnement.
ExecuteEvaluationUseCase occupe le premier niveau. Il reçoit la configuration complète d'une évaluation. La suite du travail, c'est de faire tourner cette configuration : exécuter les passes dans le bon ordre, exécuter les règles de chaque passe en parallèle, collecter les résultats. Ce sont deux problèmes distincts, à deux niveaux de granularité différents. J'ai refusé de les mélanger dans une seule classe.
DAGExecutionOrchestrator occupe le deuxième. Il raisonne sur l'ensemble des passes et leur ordre d'exécution. Certaines passes dépendent d'autres ; il doit les ordonner, paralléliser celles qui peuvent l'être, attendre celles qui ne le peuvent pas. Il ne sait rien de ce qu'est une règle. Pour lui, une passe est une unité opaque qu'il délègue à l'orchestrateur du niveau suivant.
PassExecutionOrchestrator occupe le troisième. Il raisonne sur une passe unique et l'ensemble de ses règles. Il reçoit une passe et une configuration, il instancie AgentService pour chaque règle, il collecte les RuleResult produits. Il ne sait rien du DAG qui l'appelle, ni des passes qui viendront après lui. Pour lui, une évaluation est réduite à une passe et à un ensemble de règles.
Le dernier niveau, c'est la rangée des AgentService. C'est là que le Transient de l'épisode précédent trouve son sens concret. PassExecutionOrchestrator demande une nouvelle instance d'AgentService pour chaque règle qu'il évalue. NestJS instancie en cascade AgentService, LoopDetector, StructuredOutputHandler. Chacune de ces instances porte l'état d'une règle et d'une règle seulement. Quand la règle se termine, ces instances disparaissent. La règle suivante démarre sur une ardoise propre.
Quatre niveaux, autant d'ignorances. Le use case ne sait pas comment une passe s'exécute en interne. Le DAG orchestrator ne sait pas comment une règle est évaluée. Le pass orchestrator ne sait pas ce qu'une règle signifie pour AgentService. AgentService ne sait pas qu'il participe à une évaluation. Chaque couche ne connaît que la suivante, et cette ignorance est ce qui permet à chacune d'évoluer sans déstabiliser les autres.
Remonter vers le verdict
AgentService rend un RuleResult. Ce résultat n'est pas un score. C'est une liste d'évidences brutes : les points de vérification atomiques qui ont été confirmés ou infirmés, les niveaux de confiance attachés à chaque évidence, le raisonnement qui a conduit à ces conclusions, le nombre de tool calls effectués, les tokens consommés. Tout est là, sauf le score.
Le score, c'est l'affaire d'EvaluationModule. Cette frontière m'a pris du temps à formuler clairement, mais une fois posée, elle a rendu les deux côtés plus simples à concevoir. AgentService produit des évidences. EvaluationModule les traduit en scores, en décisions, en verdicts. L'un observe le code ; l'autre interprète ce qu'il a vu.
Trois services de domaine portent cette traduction. BonusScoringService applique les règles de bonus configurées sur les scores bruts. ConditionEvaluatorService évalue les conditions de passage : un seuil de score, une règle obligatoire, une combinaison de critères. DecisionGeneratorService produit les décisions finales à partir des scores et des conditions évaluées. Ensemble, ils transforment une collection d'évidences atomiques en un résultat d'évaluation interprétable.
Pendant que cette transformation s'opère, EvaluationModule parle. Il ne travaille pas en silence. Quatre événements rythment son cycle de vie, publiés sur l'exchange RabbitMQ evaluation-events. evaluation.started signale le démarrage effectif du job. evaluation.progress est émis à la fin de chaque passe, pour que le front-end puisse afficher la progression. evaluation.completed porte le verdict final. evaluation.failed porte l'erreur qui a interrompu l'évaluation. Ces événements ont deux destinations : le gateway, qui les bridge vers les WebSockets du front-end, et le micro-service graph (arangoDB), qui reçoit les événements terminaux pour alimenter le graphe de compétences.
La prochaine fois : EvaluationModule orchestre. Mais l'ordre dans lequel il fait tourner les passes n'est pas arbitraire : il suit un graphe de dépendances. Certaines passes peuvent tourner en parallèle, d'autres doivent attendre. La prochaine fois, on entre dans le DAG : comment un graphe statique devient un plan d'exécution dynamique.