La vie intérieure d'un module
Un service sans état peut être partagé. Un service avec état doit être seul.
L'épisode précédent a posé la structure et laissé une question ouverte : combien de temps vit chaque service ? La structure des modules dit quoi, pas quand. Pour savoir quand, j'ai dû entrer à l'intérieur d'AgentModule et regarder chaque service en face.
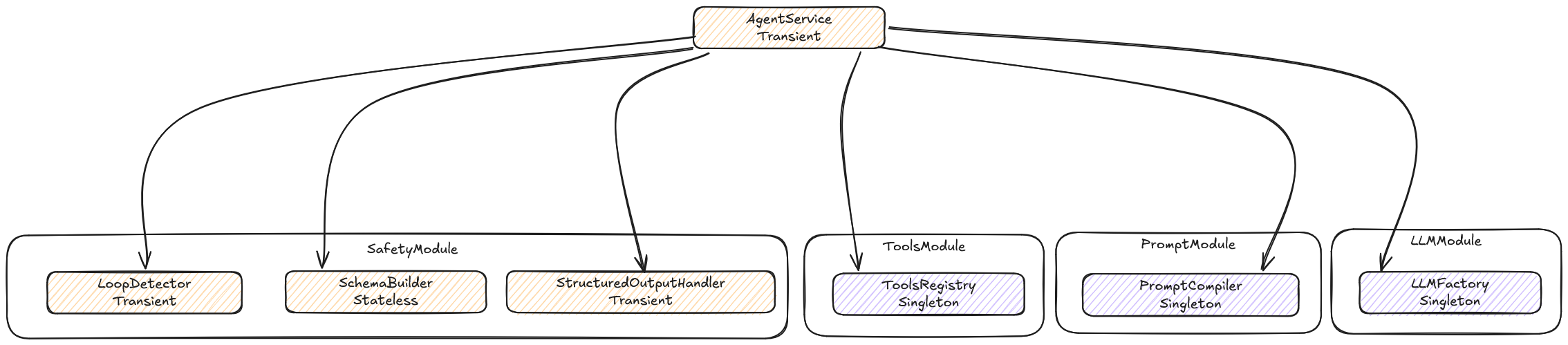
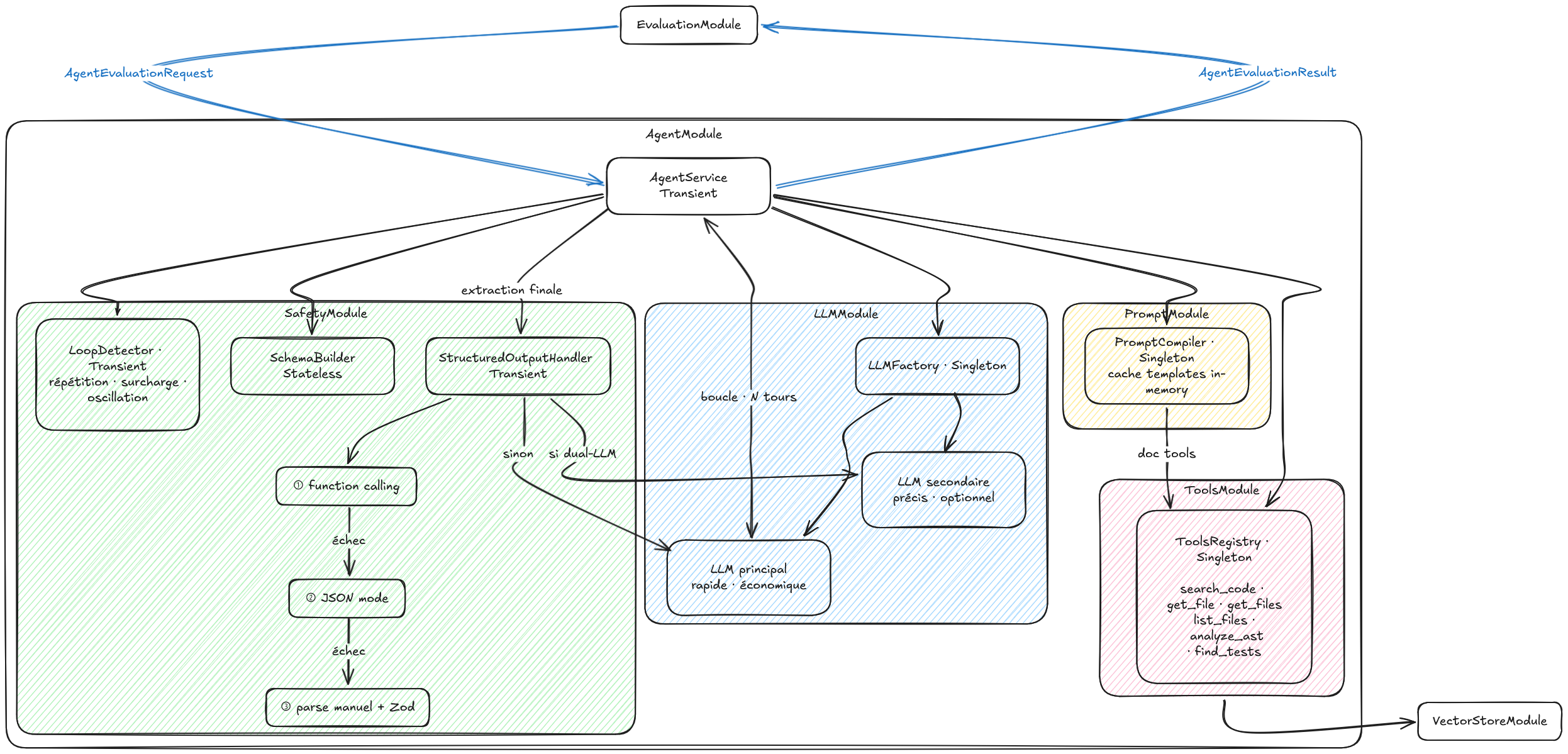
AgentModule est le moteur d'AgenticLayer. C'est lui qui fait tourner la boucle agentique : recevoir un contexte, compiler un prompt, appeler un LLM, exécuter des tools, surveiller les dérives, extraire un résultat structuré. Sa structure interne regroupe quatre sous-modules aux responsabilités distinctes : LLMModule résout le bon client selon le provider configuré, ToolsModule tient le registre des outils disponibles, PromptModule assemble le prompt à envoyer, SafetyModule surveille ce que la boucle ne devrait pas faire.
Ce que cette structure ne dit pas encore, c'est comment ces sous-modules se comportent à l'exécution. AgenticLayer évalue en parallèle : une évaluation complète peut déclencher quarante règles simultanément, chacune avec sa propre boucle, son propre historique de messages, ses propres patterns de tool calls. Si deux de ces boucles partagent accidentellement la même instance de LoopDetector, la mémoire de l'une contamine l'autre. Le LLM de la première règle a appelé search_code trois fois de suite ? LoopDetector le sait. Si la deuxième règle utilise la même instance, elle hérite de ce compteur : LoopDetector va détecter une répétition qui n'existe pas dans son exécution. Aucune erreur levée. Un comportement incorrect, visible uniquement sous charge, difficile à reproduire.
C'est pourquoi la question du scope n'est pas une question d'organisation du code. C'est une question de correction du système.
La réponse, pour chaque service, se lit dans ce qu'il fait. ToolsRegistry est un registre statique : à l'initialisation du module, il reçoit les six tools enregistrés dans ToolsModule (search_code, get_file, get_files, list_files, analyze_ast, find_tests), et cet état ne mute plus jamais. Deux évaluations qui tournent en parallèle lisent le même registre sans interférence, non pas parce qu'elles sont bien synchronisées, mais parce qu'il n'y a rien à synchroniser. ToolsRegistry est Singleton parce qu'il n'a pas d'état par exécution.
LoopDetector est l'inverse. Sa raison d'être est de se souvenir : les derniers tool calls, leurs paramètres, leur fréquence, dans cette exécution précise. Il est Transient parce qu'il est son état. SchemaBuilder échappe à la question entièrement : il génère à la volée le schéma Zod de validation depuis la configuration YAML d'une règle, une transformation pure sans mémoire entre les appels, dont les méthodes sont statiques. On pourrait lui attribuer un scope ; ce serait une fiction.
LLMFactory et PromptCompiler sont Singleton pour une raison différente. Ils portent un état (LLMFactory résout les clés API via ConfigService, PromptCompiler maintient un cache in-memory des templates déjà lus depuis le système de fichiers), mais cet état est initialisé une fois et ne mute plus. Deux évaluations parallèles lisent le même cache de templates sans risque : le cache est une optimisation, pas un canal de communication.
La chaîne qu'on n'avait pas vue
J'avais déclaré LoopDetector Transient. Et StructuredOutputHandler Transient. Les annotations étaient là, dans le code, correctement placées.
Puis j'ai relu la documentation de NestJS sur les scopes. Je me suis arrêté.
NestJS ne propage pas les scopes dans le sens qu'on imagine. Ce n'est pas le scope le plus court qui l'emporte : c'est le plus long. Si AgentService est Singleton et qu'il injecte LoopDetector Transient, NestJS instancie LoopDetector une seule fois au démarrage. L'annotation Transient est là, dans le fichier, mais elle ne fait rien. Le provider Transient adopte le cycle de vie de son consommateur le plus stable.
Pour que LoopDetector soit effectivement recréé à chaque exécution, son consommateur direct doit lui-même être Transient. AgentService porte l'historique d'une boucle, l'état courant de l'extraction, les messages échangés avec le LLM. Il devait être Transient de toute façon. Mais maintenant, ce n'est plus seulement une bonne pratique : c'est une condition. Sans AgentService Transient, les déclarations Transient de LoopDetector et StructuredOutputHandler seraient des ornements sans effet.
Retour de R&D : en NestJS, un
@Injectable()est Singleton par défaut : une seule instance partagée entre tous les modules qui l'injectent. Pour déclarer un scope Transient, on écrit@Injectable({ scope: Scope.TRANSIENT }). La conséquence non évidente : si un provider Singleton injecte un provider Transient, le Transient est instancié une seule fois au démarrage. Il perd son caractère transient. NestJS appelle cela la scope chain : le scope d'un provider est déterminé par le scope le plus long de ses consommateurs.AgentServiceest Transient, ce qui forceLoopDetectoretStructuredOutputHandlerà être effectivement recréés à chaque instanciation d'AgentService. DéclarerLoopDetectorTransient sans que son consommateur le soit aussi n'aurait rien changé.
L'hypothèse fragile
La boucle fait une hypothèse : le LLM répondra dans le format attendu. Cette hypothèse est raisonnable. Elle n'est pas toujours tenue.
StructuredOutputHandler est la réponse à ce que le LLM fait quand il ne coopère pas. Sa chaîne de fallback descend en trois niveaux. Le premier est le function calling natif : la méthode préférentielle pour Anthropic et OpenAI GPT-4, qui garantit une réponse structurée par contrat avec le modèle. Le second est le JSON mode : un mode explicite de certains providers (GPT-3.5, Azure, LiteLLM) qui demande au modèle de répondre en JSON sans garantir la structure exacte. Le troisième est le parse manuel, une combinaison de regex, JSON.parse et validation Zod, qui tente d'extraire quelque chose de sensé d'une réponse en langage naturel. Ce dernier niveau est le recours ultime : la preuve qu'on a pensé à ce que le LLM pourrait faire de pire.
StructuredOutputHandler est Transient non pas parce qu'il accumule de l'état au fil de la boucle, mais parce qu'il est lié à une instance LLM spécifique à une exécution. Deux règles évaluées avec des providers différents ont deux handlers distincts, chacun calibré pour les capacités déclarées de son provider.
LoopDetector, de son côté, surveille trois patterns. La répétition exacte : même tool, mêmes paramètres, N fois consécutives. La surcharge : même tool appelé trop souvent sur une fenêtre glissante d'appels. L'oscillation : alternance régulière entre deux tools sans convergence. Sur détection, il injecte un message dans la conversation. Non pas une interruption brutale : une indication que quelque chose ne va pas, qui laisse à l'agent la possibilité de corriger sa trajectoire lui-même.
Le deuxième cerveau
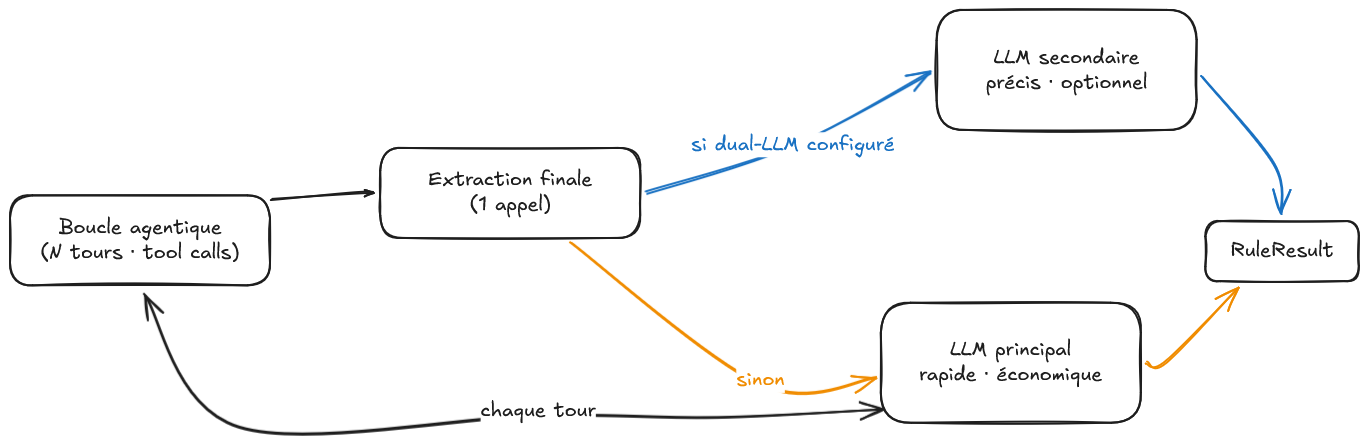
Il y a une décision qui ne se lit pas dans un graphe de dépendances. AgentService peut recevoir deux configurations LLM distinctes : un modèle principal pour la boucle agentique, un modèle secondaire pour l'extraction de la sortie structurée en fin de boucle.
La raison est économique autant que technique. La boucle fait de nombreux appels LLM, chaque tour, chaque réponse à un tool call. Utiliser à chaque fois le modèle le plus capable serait coûteux et lent pour des opérations qui ne l'exigent pas : lire un fichier, chercher un pattern, construire progressivement une liste d'évidences. L'extraction finale est différente. Elle demande que le modèle suive un schéma Zod précis, avec des contraintes de validation strictes sur les IDs de checkboxes, les niveaux de confiance, les longueurs minimales de raisonnement. C'est là que la précision compte. C'est là qu'un modèle plus capable vaut son coût.
La configuration dual-LLM est optionnelle : si un seul modèle est fourni, il fait tout. Mais la possibilité de les dissocier est là, pensée dès le début, parce que le coût d'un agent n'est pas une constante.
Ce que le contrat ferme
AgentModule s'expose au reste du système à travers deux interfaces.
AgentEvaluationRequest porte ce que le module reçoit : la configuration de la règle, le prompt compilé, le contexte des tools (collection Qdrant, chemin du dépôt, identifiant d'évaluation pour le cache Redis), la configuration de la passe. AgentEvaluationResult porte ce qu'il rend : le verdict structuré de la règle, le nombre de tool calls, les tokens consommés, la durée d'exécution.
Ce que EvaluationModule sait d'AgentModule, c'est exactement ça, et rien d'autre. Il ne sait pas quel LLM a été utilisé. Il ne sait pas combien de tours a pris la boucle. Il ne sait pas si LoopDetector a détecté quelque chose, ni si StructuredOutputHandler a dû descendre jusqu'au parse manuel. Ces détails sont capturés dans les traces Langfuse, pas dans le contrat. Le contrat expose le résultat. L'implémentation reste opaque.
C'est ce que "module" signifie, poussé jusqu'au bout : non pas un répertoire bien rangé, mais une frontière qui protège les deux côtés de ce qu'ils n'ont pas besoin de savoir.
La prochaine fois : AgentModule est refermé sur lui-même : ses services nommés, leurs scopes déclarés, leurs contrats posés. Ce qui reste, c'est ce qui l'orchestre : comment EvaluationModule reçoit un identifiant d'évaluation et en fait quarante règles évaluées en parallèle, comment les passes s'enchaînent selon un DAG, comment un verdict global émerge de tout cela. La prochaine fois, on monte d'un niveau.