La carte avant le territoire
Un système se comprend d'abord par ses frontières, avant de se comprendre par son contenu.
Avant d'écrire la première ligne de code, j'ai dû répondre à une question que je pensais secondaire : comment découper le système ? Non pas dans le détail de chaque composant, mais dans la logique qui préside à leur séparation. Car chaque frontière tracée entre services est la réponse à une contrainte et comprendre la contrainte, c'est comprendre pourquoi le système ressemble à ce qu'il est plutôt qu'à autre chose.
Ce que chaque service n'a pas à savoir
Tout mettre dans un seul monolithe aurait été plus simple. Un seul processus, un seul déploiement, une seule base de code à maintenir. La tentation du monolithe n'est pas irrationnelle, notamment en début de projet, quand la complexité de coordination entre services coûte plus qu'elle ne rapporte.
Or j'ai compris assez vite que ce chemin serait difficile à tenir sur la durée. Non pas par doctrine, mais par une divergence concrète de contraintes. Un service qui fait de l'inférence LLM (appels à des APIs externes), boucles agentiques de plusieurs minutes, pic de mémoire au moment du traitement, n'a pas les mêmes besoins qu'un service qui répond à des requêtes de graphe en quelques dizaines de millisecondes. Les scaler ensemble serait inefficace. Les faire évoluer au même rythme, alors que l'un change à chaque nouvelle capacité LLM et que l'autre suit la stabilité du modèle de données, serait une source de friction permanente.
La frontière entre services ne s'est donc pas tracée par convention. Elle suit une ligne de fracture naturelle entre des domaines qui ont des cycles de vie, des ressources et des responsabilités fondamentalement distincts. Ce que chaque service gagne à ne pas savoir de l'autre, c'est précisément ce qui lui permet d'évoluer sans le contraindre.
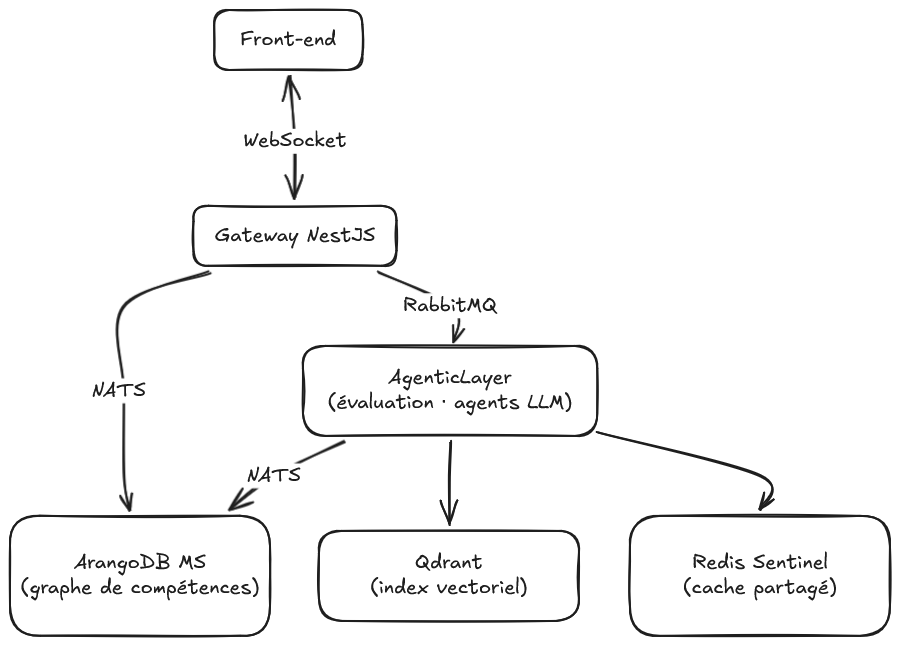
Retour de R&D: une architecture microservices découpe un système en services autonomes qui communiquent via des messages ou des appels réseau. L'avantage est l'indépendance : chaque service peut être déployé, mis à jour ou mis à l'échelle sans toucher aux autres. La contrepartie est réelle : il faut gérer la communication entre services, les pannes partielles, la cohérence des données distribuées. Ce n'est pas une solution universelle �— c'est un compromis qui devient pertinent quand les contraintes de chaque composant divergent suffisamment pour que les coupler soit un problème.
Ce qu'un seul broker ne peut pas promettre
Je me suis posé la question, et elle était légitime : pourquoi deux brokers de messages ? Un seul ne suffirait-il pas ?
RabbitMQ seul semblait d'abord défendable. Il est capable de gérer des échanges rapides via un pattern RPC avec queue temporaire, correlation ID, réponse asynchrone. On peut construire quelque chose qui ressemble à du request/reply. Mais en creusant, quelque chose résistait. RabbitMQ est conçu pour garantir. Sa valeur est dans la persistance, dans le routage, dans la certitude que le message sera traité même si le destinataire n'était pas disponible au moment de l'envoi. Lui demander de la vitesse sub-milliseconde, de la légèreté, du dialogue synchrone entre services, c'est lui faire porter ce qui n'est pas sa nature. Sous charge, les queues temporaires, les correlation IDs, la gestion des réponses orphelines introduisent une friction que rien ne justifie pour des échanges qui, par nature, n'ont pas besoin d'être durables.
L'inverse a aussi été envisagé : NATS seul, avec JetStream pour la persistance. La solution était propre sur le papier. Mais JetStream aurait demandé une configuration spécifique sur une infrastructure NATS déjà en production pour d'autres usages. Une modification à risque pour une promesse que RabbitMQ tient nativement, sans détour. Kafka, lui, a été écarté plus tôt dans la réflexion : conçu pour des millions d'événements par seconde, avec un modèle de partitions et de consumer groups qui ne trouve sa justification qu'à une échelle que ce système n'atteindra pas avant longtemps (non sans une certaine nostalgie), car Kafka a l'élégance des outils prévus pour des problèmes qu'on ne rencontre pas encore.
Ce qui s'est imposé, finalement, c'est une distinction de nature plutôt que de performance. Deux types d'échanges coexistent dans ce système, et ils n'ont pas les mêmes besoins.
Le premier est éphémère : un service en interroge un autre, reçoit une réponse, et le message n'a plus aucune valeur ensuite. NATS est fait pour cela: rapide, léger, sans overhead de persistance. Le second dure : une évaluation peut prendre plusieurs minutes, et si AgenticLayer est momentanément indisponible au moment du déclenchement, le message ne peut pas disparaître. RabbitMQ garantit qu'il sera traité. Que ce soit dans dix secondes ou dans dix minutes, après un redémarrage ou après une saturation passagère le job sera là.

La règle est simple : ce qui peut être perdu sans conséquence passe par NATS. Ce qui ne peut pas l'être passe par RabbitMQ.
Retour de R&D : choisir un broker de messages, c'est choisir un contrat de livraison. NATS dit : "je fais de mon mieux, mais si le destinataire n'est pas là, le message disparaît". RabbitMQ dit : "je garde le message jusqu'à ce qu'il soit traité, et si ça échoue, je sais quoi faire". Ces deux contrats ne sont pas interchangeables: l'un est adapté aux échanges éphémères et rapides, l'autre aux tâches qui ont de la valeur même plusieurs minutes après avoir été déclenchées.
Chercher le sens, pas le mot
L'écosystème est posé. Mais ce qu'AgenticLayer doit faire concrètement, c'est analyser un objet extérieur (en autre chose) : le dépôt de code soumis par un candidat. Et là, la question du stockage prend une autre forme.
La première tentation, face à un dépôt à analyser, est d'y chercher des mots. Des patterns, des structures syntaxiques, des correspondances textuelles. Les outils existent (grep, les index full-text, les requêtes sur l'AST), ils sont précis, rapides, et répondent bien aux questions dont on connaît déjà la formulation exacte.
Or les questions que je voulais poser à ce code ne ressemblaient pas à cela. "Les abstractions sont-elles cohérentes à travers les couches ?" "La gestion des erreurs révèle-t-elle une intention ou une improvisation ?" Ce sont des questions de sens, pas de syntaxe. Elles n'ont pas de traduction lexicale directe, aucune correspondance de texte ne peut y répondre.
C'est là qu'intervient la recherche vectorielle. Chaque fragment de code est transformé en une représentation numérique qui encode son sens, sa sémantique, son contexte, ce qu'il fait plutôt que ce qu'il écrit. Qdrant stocke ces représentations et permet de retrouver les fragments les plus proches d'une requête exprimée en langage naturel, par similarité de sens plutôt que par correspondance de termes.
D'autres bases de données vectorielles existent: Pinecone, Weaviate, Chroma, et quelques autres que j'ai sérieusement envisagé de comparer en détail avant de me rappeler que j'avais un système à construire. Le choix de Qdrant tient à sa nature : open source, auto-hébergeable, avec une API claire et un modèle de filtrage qui permet de combiner recherche sémantique et critères structurels.
Retour de R&D : un vecteur est une liste de nombres qui représente le "sens" d'un texte dans un espace mathématique. Deux textes proches par le sens auront des vecteurs proches dans cet espace, même s'ils ne partagent aucun mot. C'est ce que font les modèles d'embedding : transformer du texte en vecteurs. Et c'est ce que font les bases de données vectorielles comme Qdrant : stocker ces vecteurs et trouver rapidement les plus proches d'une requête. La recherche sémantique est la combinaison des deux.
La mémoire commune
Redis est un cache, une mémoire rapide qui évite de refaire un travail déjà accompli. Redis Sentinel est sa version haute disponibilité, avec réplication et bascule automatique en cas de panne.
Ce qui rend son rôle ici particulièrement structurant, c'est qu'il est partagé entre toutes les instances d'AgenticLayer et entre tous les agents qui y tournent simultanément. Quand un agent lit un fichier depuis Qdrant, le résultat est mis en cache. Si un second agent sur une autre instance, pour une autre évaluation, lit le même fichier depuis la même collection, il trouve directement le résultat en cache, sans solliciter Qdrant.
Or ce n'est pas simplement une optimisation de performance. C'est une décision d'architecture : le cache n'appartient pas à un agent particulier, ni à une évaluation particulière. Il appartient à la couche d'infrastructure qui médiatise tous les accès à Qdrant. Cette distinction, en apparence subtile, a des conséquences profondes sur la façon dont chaque composant est conçu. Un agent qui sait qu'il partage sa mémoire avec d'autres agents n'est pas conçu de la même façon qu'un agent qui croit être seul.
L'héritage et ce qui reste
Je n'ai pas conçu AgenticLayer dans le vide. Les choix de transport, de persistance graphique, d'authentification: ils existaient avant lui, pensés pour la plateforme dans son ensemble. AgenticLayer les reçoit en héritage. Il doit s'y inscrire sans les contrarier, parler les mêmes langues, respecter les mêmes contrats.
C'est une contrainte. Mais c'est aussi, d'une certaine façon, une forme de clarté : les problèmes déjà résolus n'ont pas à être résolus à nouveau.
L'espace de conception d'AgenticLayer est délimité par ce qui lui précède. Mais dans cet espace, il reste une décision que rien n'impose encore : dans quelle language écrire ce service ?
La prochaine fois : L'écosystème est posé. Mais avant de l'habiter, il faut choisir dans quelle langue lui parler... Une question qui semble évidente et qui ne l'est pas. Pourquoi TypeScript pour un service dont le cœur est agentique, quand Python règne sur l'écosystème LLM ? La prochaine fois, le choix du langage et du framework : deux décisions que l'on prend souvent par réflexe, et que j'ai eu envie de défendre par conviction.